Structured Buffer Vs Constant Buffer
CG 로 쉐이더 코딩을 하기 위해 여러 소스와 웹페이지를 뒤지던 도중 재미있는 글을 발견했다. HLSL 에서 사용하는 StructuredBuffer 와 Constant Buffer 의 차이에 대한 글이였다. Unity 메뉴얼을 따라가면서 몇번 보긴했지만 무슨 차이인지도 모르는 것들이였다. 하지만 알고나니 GPU Instancing 에 대한 기본적인 상식이기에 글을 쓴다. 우선 두가지를 먼저 간단하게 알아보고 두 개념의 차이에 대해서 알아보자.
Constant Buffer
이름을 직역하면 상수 버퍼다. 직관적인 느낌은 단순한 고정값 참조를 위한 버퍼인 것 같다.
cbuffer 는 gpr(general purpose register) 에 내용을 복사한 이후에 사용하는 듯 하다. 번호를 정하는 부분에서 레지스터 키워드를 확인할 수 있다. 레지스터를 사용했으니 VRAM 에서 데이터를 가져오는 것보단 빠를것이고, 많은 데이터는 넣지 못할것으로 추측된다. 단순히 읽기만 되므로 값을 쓸때의 퍼포먼스는 고려하지 않아도 된다.
Unity 에서는 GPU Instancing 기본 예제를 DirectX 의 경우에는 cbuffer 를 사용하게 한다. 아래처럼 선언하게 되어 있다.
UNITY_INSTANCING_CBUFFER_START(_CBufferName)
...
UNITY_INSTANCING_CBUFFER_END
전처리가 끝나서 HLSL 식으로 컨버팅되면 아래와 같이 된다. Unity 에서 제공하는 쉐이더 코드를 참조했다.
cbuffer _CBufferName {
...
}
Unity 에서 제공하는 예제는 단순하게 컬러값을 인스턴스별로 바꾸게 해주는 그리하여 여러개의 메터리얼을 사용하지 않아 쓸데없는 SetPass 를 안하게 해주는 예제다.
하지만 cbuffer 가 GPR 을(register) 사용하는 것이기 때문에 저장할 수 있는 데이터의 갯수는 비교적 적다. 기본적으로 사용할 수 있는 레지스터 공간 자체가 별로 크지 않기 때문이다. 만약 전체 크기를 넘어간다면 할 수 있는 가정은 메모리에서 데이터를 가져와 사용할때 마다 갱신하는 것인데, 이는 꽤 큰 코스트가 될 것으로 보인다. 특히 배열의 형태의 모든 쓰레드가 다른 데이터를 접근할 때 하나하나 데이터를 가져오면 굉장히 느려질 것이다.
만약에 cbuffer 와 로컬변수가 같은 GPR 들을 사용하게 된다면 실행내내 유지되는 로컬변수의 갯수에 따라서 실행할 수 있는 Thread 의 수 또한 줄게된다. 이 역시 성능 하락에 영향을 미칠것이다.
StructuredBuffer
다음으로 알아볼 것은 StructuredBuffer 다. 앞에서 언급한 cbuffer 와는 다른 syntax 와 다른 기능을 가지고 있다. unity 의 CG/HLSL 의 StructuredBuffer syntax 는 다음과 같다.
struct vertex
{
float3 position;
float3 normal;
}
StructuredBuffer<vertex> perVertexDataBuffer;
v2f vert (uint vertexID : SV_VertexID)
{
vertex v = perVertexDataBuffer[vertexID];
...
return someData;
}
StructuredBuffer 는 기본적으로 우리가 아는 CPU 에서의 메모리 접근 방식처럼 작동하는 것으로 보인다. DRAM 의 주소를 사용해 데이터를 가져오고, L1,L2 캐시를 통해 캐싱을 하는 “일반적인” 접근 방식 말이다. 꽤 많은 큰 데이터를 접근할 때는 이 방법을 써야할 것으로 보인다. 그리고 StructuredBuffer 를 쓸때 알아야할 사실은 해당 struct 의 구조가 128bit 단위로 크기를 가져야 효율적인 작동을 기대할 수 있다고 한다. 이는 아마도 데이터를 가져올 떄 128bit 씩 가져오는 것으로 예상할 수 있겠다.
성능을 중요시 한다면 해당 자료형의 크기 또한 중요하다. 조금만 찾아보면 stride 의 크기는 적어도 128 bit 단위여야 한다고 써있는 자료를 볼 수 있다. 아마도 이는 VRAM 과 cache 에서 4byte 단위로 잘라서 처리하기 때문이라고 한다. 만약에 stride 를 맞추지 않는다면 꽤 많은 데이터를 쓸데없이 메모리에서 가져와야 할 수도 있다.
결론은 간단하다. 데이터의 크기가 작을 때는 Constant Buffer, 데이터의 크기가 클 때는 StructuredBuffer 를 사용하면 된다. Constant Buffer 는 레지스터를 사용해서 빠르지만 가지고 있을 수 있는 데이터의 크기가 작고, StructuredBuffer 는 메모리 접근을 하기 때문에 느리지만 엄청나게 많은 데이터에 접근할 때는 어쩔 수 없는 차선책이다. 물론 GPU 구조에 따라서 달라질 수도 있다(PC 용, 모바일용, 콘솔용)
Compute Shader 를 사용할 때 StructuredBuffer 를 사용하면 다음과 같은 차선책이 존재한다.
StructuredBuffer<Light> LightBuf;
groupshared Light[MAX_LIGHTS] LocalLights;
LocalLights[ThreadIndex] = LightBuf[ThreadIndex];
GroupSharedMemoryBarrierWithGroupSync();
for (int i = 0; i < num_lights; i++)
{
Light cur_light = LocalLights[i];
// Do Lighting
}
출처 : NVidia developers : Redundancy and Latency in Structured Buffer Use
Constant Buffer 에 넣기도 애매하고 StructuredBuffer 에 넣기도 애매한 데이터의 갯수가 Thread Size 를 넘지않는 데이터는 위와같이 Shared Memory 를 사용하여 데이터를 캐싱하여 사용할 수 있다. Shared Memory 는 보통 cache 와 같은 SRAM 에, 각 Thread Group 별로 하나씩 가지고 있는 변수로, 위처럼 물리적인 특징을 사용해 cache 로 사용하거나, Thread Group 안에서 데이터를 R/W 시에 사용되는 방식이다.
※ 추가로 해당 글은 수정된 글입니다. 조금 하드웨어적인 부분에 대하여 내용을 수정하던 도중 Yosogames : Uniform buffers vs texture buffers: The 2015 edition 에서 Constant Buffer 에 배열에 각기 다른 데이터를 접근할 때 느려진다는 사실은 꽤 오래전 이야기라고 해서 뒤의 결론은 전부 취소선 처리했습니다. 이 글을 지금 보신다면 밑의 내용은 읽을 필요없고, 이전에 보았다면 꽤 오래전 이야기인것을 알아야 합니다.
HLSL Assembly Analysis
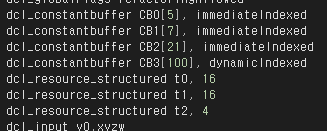
이는 Constant Buffer 와 StructuredBuffer 의 레지스터 선언 내용으로, Constant Buffer 는 세부적인 내용과 immediateIndexed, dynamicIndexed 키워드를 통해 레지스터에서 사용된다는 것으로 예측했다. 반면에 StructuredBuffer 의 선언부는 굉장히 간단하다. 아마도 StructuredBuffer 의 RAM 안의 주소를 t0 ~ t2 레지스터안에 저장하는 것으로 예측된다.
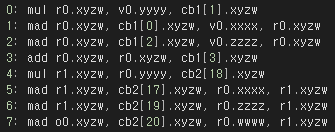
또한 immediateIndexed 가 GPU 내부에서 컴파일될떄 고정될 것으로 예상해서 Constatn Buffer 가 레지스터에 저장된다는 것을 예측하게 해준 것 중 하나다.

Constant Buffer 와 달리 데이터에 접근하는 명령어가 굉장히 복잡하다. ld_structured_indexable 의 형태는 다른 데이터 형태에(텍스쳐) 접근할 때에도 비슷한 명령어가 보인다.
참조
- MSDN : Shader Constants
- MSDN Reference : StructuredBuffer
- MSDN : New Resource Types
- AMD Developer Central : DirectX 11 Performance Reloaded
- Redundancy and Latency in Structured Buffer Use
- GTC 2010 : DirectCompute Optimizations and Best Practices
- Yosogames : Uniform buffers vs texture buffers: The 2015 edition