Gpu Branching And Divergence
요즘은 꽤나 많은 것들을 GPU 로 처리할 수 있다. GPGPU 기술이 나온지 10년이 넘어가는 이 시점에서 꽤나 많은 것들이 GPU 로 처리되고 있다. 그 중에서도 GPGPU 를 다뤄볼 사람이라면 필수적인 상식하나가 있다. 아래 그림을 보자.
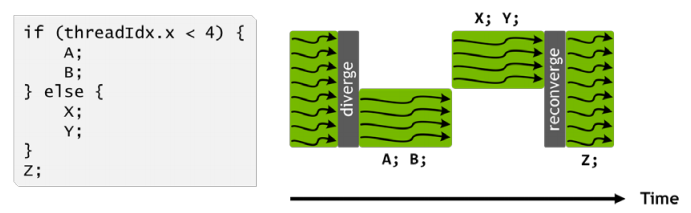
위 그림은 분기가 나뉘어져 있는 코드를 여러개의 스레드가 실행하는 것을 보여준다. 즉 GPU 에서의 코드 실행 모습이다. 왼쪽은 스레드의 번호로 나뉘는 간단한 분기 코드다. 이는 CPU 에서는 크게 문제가 없다. 하지만 분기가 있던 말던 모든 명령어들을(분기안의 코드들) 전부 실행시키는 것이다. 오른쪽의 그림에서 설명하는 것은 이를 실행하는 쓰레드의 모습을 나타낸다. 딱 봐도 이 그림은 처리가 비효율적일 것처럼 보인다.
CPU 는 한 쓰레드에서 하나의 Program Conter 를 가지기 때문에 분기가 나오면 조건에 맞게 단순히 포인터를 증가시키기만 한다. 하지만 SIMT(Single Instruction Multiple Threads) 의 구조를 가진 GPU 에서의 분기는 조금 다르다. 여태까지는 여러개의 쓰레드를 가진 그룹 하나당 Program Counter 를 가지는게 일반적이였다. 그래서 위와같이 동시에 활성화된 쓰레드들 끼리만 실행하게 되는 것이다.
Volta 아키텍쳐에서는 이를 개선시켜 한 Thread 당 하나의 Program Counter 와 Call-Stack 을 두므로써 각 Thread 를 독립적으로 실행시키게 해준다고 한다. SIMT 의 Concurrency 를 고려하여 전부 한꺼번에 실행시키지는 못하지만 각각의 Thread 를 같은 명령별로 그룹지어 실행시키거나, 한번에 실행시키는게 아니라 각 그룹의 실행을 클럭이나 시분할로 쪼개어 실행하는 것들을 지원한다고 한다. 아래 그림을 보자.
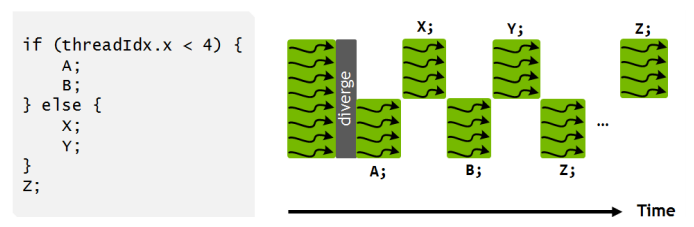
하지만 이는 그림에서 나와 있다시피 그다지 효율적인 실행은 아니다. 결국 아직은 분기의 사용은 최소화해야될 것으로 보인다. 다만 이 기능들은 Graphic Processing Unit 들이 Accelerator 로 바뀌는 하나의 과정으로 볼 수 있을듯 하다.