-
Loop Attributes For Dynamic Branching
Programmable Shader 를 작성할 때에는 한가지 유의해야 할 점이 있다. 이는 Dynamic Branching 이라는 개념이다. Dynamic Branching 은 조건 분기문이 Programmable Shader 에서 사용될 때 나타나는 현상을 말한다. Programmable Shader 는 직렬이 아닌 병렬로 실행되기 때문에 나타나는 특성이다. 반복문에서도 조건 분기를 사용한다. 간단한 아래 코드를 보자.
int i = 0; while(i < 5) { i++; }위 코드는 프로그래밍을 입문할때 볼 수 있는 코드다. 중요한 것은 while 단어가 있는 줄에 있는 조건 식이다. (i < 5) 조건식 때문에 Dynamic Branching 이 발생한다. 이 Dynamic Branching 을 명시적으로 없에거나 만들기 위해 hlsl 에서 attribute 를 지원한다. 아래를 보자.
[Attribute] for ( Initializer; Conditional; Iterator ) { Statement Block; }해당 구문은 MSDN : for Statement 에서 가져왔다. 일반적으로 프로그래머이 정말 많이본 for 반복문이다. 우리가 봐야할 것은 for 구문 왼쪽의 [Attribute] 라는 구문이다. 이 부분에는 총 4가지의 옵션을 넣을 수 있는데, 이 글에서 언급할 [Attribute] 는 두가지다. unroll 과 loop 이 두가지이다.
hlsl 로 정상적인 반복문 실행을 하게되면, 매번 반복을 할때 마다 조건식을 검사하게 되고, 해당 반복문의 범위를 마음대로 조정하여 코딩을 할 수 있다. 다만 조건식의 범위가 매번 달라진다면 Dynamic Branching 이 발생하게 된다. 그리고 반복문이 매번 Programmable Shader 가 실행될 때 상수로 반복을 한다면 쉐이더 컴파일러는 최적화를 위해 특정한 행동을 하게 된다. 아래 코드를 보자.
for(int i = 0; i < 5; i++) { }위의 코드는 루프를 다섯번 실행시키는 코드다. 따로 안에 인덱스 i 를 건드리지 않는다면 쉐이더 컴파일러는 컴파일 시점에 최적화를 한다. 이를 unroll 이라고 부를 수 있는데, 실행할 반복문을 반복문으로 해석하는게 아닌 5번 연속해서 같은 행동을 하게 하는 것이다. 조건 자체도 없어지고 그저 인덱스를 풀어쓰게 된다. 이는 상수(constant)로 반복문을 제어하면 쉐이더 컴파일러가 알아서 해주기 때문에 신경써주지 않아도 된다. 다만 unroll 이라는 키워드를 써서 바뀔 때는 변수를 사용해 반복문을 제어할 때다. 변수를 사용하면 컴파일 시점에서는 추측할 수 없기 때문에 암시적으로 unroll 을 할 수 없다. 이 때 unroll 키워드를 사용하여 제어할 수 있다.
int count = ...; [unroll(5)] for(int i = 0; i < count; i++) { }또한 암시적으로 unroll 된 반복문을 명시적으로 반복문으로 실행되게 할 수도 있다.
[loop] for(int i = 0; i < 5; i++) { }참조 자료
-
Introduce Of Wave Programming
Windows 10 Fall Creators Update 가 나오면서 Shader Model 6.0 이 추가되었다. 여태까지의 Shader Model 업데이트는 대부분 DirectX 버젼이 올라가면서 같이 업데이트 된 경우가 많으나 이번의 Shader Model 6.0 은 따로 업데이트 되었다. Shader Model 6.0 에서의 가장 큰 기능 추가는 당연히 Wave Intrisic 이라고 할 수 있겠다. Wave Intrisic 을 제외하면 Shader Model 6.0 은 바뀐게 없다.
여태까지의 HLSL 을 사용한 쉐이더 작성은 거의 대부분 Single-Threading 으로 작동되었다. Pixel Shader 에서 ddx, ddy instrisic 을 사용하여 Gradient 데이터를 가져올 수 있긴 했지만 이 것을 제외하면 거의 없었다고 보면 되겠다. 그래서 Shader Model 6.0 에서는 다른 Thread 와 인터렉션 할 수 있는 Wave Intrisic 을 지원한다. MSDN : HLSL Shader Model 6.0 을 살펴보면 알겠지만 단순한 API 들을 제공하는 것이다. 하지만 내부에서 동작하는 것은 조금 다르다.
MSDN : HLSL Shader Model 6.0 에서 나온 용어에 대한 설명이 필요하다. Lane 은 일반적으로 생각되는 한개의 Thread 가 실행되는 것이다. Shader Model 6.0 이전의 쉐이더 모델은 단순히 Lane 개념 안에서 코딩을 해야 했다. Lane 은 상황에 따라 실행되고 있는 상태일 수도 있고, 쉬고 있는 상태일 수도 있다. Wave Intrisic 을 사용해 이를 각각의 Lane 에서도 알 수 있다. Wave 는 GPU 에서 실행되는 Lane 의 묶음을 뜻한다. 즉 여러개의 Lane 이라고 할 수 있겠다. 같은 Wave 안의 Lane 들은 Barrier 라는게 없다. 필자가 알고 있는 Barrier 는 Memory Barrier 인데, 이는 Thread(Lane)끼리의 같은 메모리에 접근하는 것에 대한 동기화를 위해 있는 개념이다. 동기화를 위한 Barrier 는 속도를 늦출 수 밖에 없다. 하지만 Wave 로 묶여진 Lane 들은 서로 Barrier 가 명시적으로 존재하지 않기 때문에 Wave 별로 빠른 메모리 접근이 가능하다는 것이다. Wave 는 Warp, WaveFront 라고도 불리울 수 있다고 한다.
그리고 이 API 들을 통해 약간의 드라이버 내부를 엿볼 수 있다. Pixel Shader 에서 Render Lane 과 Helper Lane 이 구분되어져 있는데, 이는 ddx,ddy 를 통해 픽셀의 Gradient 를 계산하는 것에 대한 보다 디테일한 개념을 생각할 수 있게 해준다. GPU 드라이버 시스템에서는 픽셀을 처리하기 위해 단순히 한개의 픽셀만 처리하는게 아닌 2x2 의 픽셀을 엮어 계산한다. 이를 MSDN 문서에서는 2x2 의 픽셀 뭉치를 Quad 라고 명칭한다. Quad 는 두가지 종류에 스레드가 실행된다. 하나는 우리가 잘 알고 있는 Pixel Shader 를 실행하는 Render Lane 이다. Render Lane 은 화면에 보여주는 색을 결과로 내놓게 된다. 그리고 나머지 한가지는 Helper Lane 인데, 이는 Pixel 별로 Gradient 를 계산하기 위해 실행되는 Lane 으로써 아무런 결과를 내놓지 않고 단순히 계산을 위한 Lane 이다.
Shader Model 6.0 은 DirectX12 과 Vulkan 에서 지원한다. DirectX 에서는 Pixel Shader 와 Computer Shader 에서 지원한다. Vulkan 에서는 모든 쉐이더 단계에서 지원한다. 그래픽 카드 벤더별로 조금씩 다른게 있으니 GDCVault(GDC 2017) : Wave Programming D3D12 Vulkan 에서 참고 바란다.
이 API 는 여러 쓰레드들 끼리 쉽게 협력하여 보다 효율적인 쉐이더 병렬 프로그래밍을 가능하게 해줄듯하다. 다만 Shader Model 5.0 에서 소개된 ComputeShader 만큼의 임팩트는 없다. 패러다임의 아주 큰 변화는 없다는 뜻이다. DirectX12 가 지향하는 드라이버 시스템에서의 부담을 줄이는 것과 Shader Model 6.0 은 서로 방향이 비슷하다고 생각된다.
추가
gpu branching and divergence에서 NVidia 의 Volta 아키텍쳐에 대해서 잠깐 언급했었다. Volta 아키텍쳐는 GPGPU 기능을 강화하기 위해 Thread 의 관리 꽤나 향상시켰다. Wave Intrisic 들은 다른 Thread 와의 처리를 도와주기 때문에 Shader Model 6.0 을 지원하는 GPU 가 나온다면 재미있는 시도들이 나올듯 하다.
참조 자료
-
Using Rendering To Cubemap
using replacement shader 에서 Camera.RenderWithShader 와 같은 렌더링을 코드에서 직접해주면서 기능을 커스터마이징 할 수 있는 것을 살펴보았는데, 이 게시물에서는 비슷한 메서드인 Camera.RenderToCubemap 에 대해서 알아볼 것이다.
Unity 에서는 여러 렌더링 커스터마이징 기능을 제공하는데, 이 게시물에서는 그 중 하나인 Camera.RenderToCubemap 에 대해서 알아볼 것이다. 일반적으로 Cubemap 은 SkyBox 나 주변의 Irradiance 를 나타낼 때 쓴다. 다만 이를 직접 구현할 때의 문제점은 각 모서리별로 Aliasing 이 일어나는 경우다. 매우 매끄러운 표면의 Specular 에서 Aliasing 이 나타난 Irradiance 를 표현하면 굉장히 티가 많이 나기 때문에 이는 굉장히 신경써야할 문제다.
그래서 Unity 에서는 Cubemap 에 렌더링을 하는 기능인 Camera.RenderToCubemap 을 지원한다. 이를 통해 할 수 있는 것은 실시간으로 Cubemap 에 렌더링된 결과를 저장해 Irradiance 의 소스로 쓰거나, 실시간으로 바뀌는 Skybox 렌더링을 할 수도 있다. 사용 방법은 아래와 같다.
RenderTexture cubmapRT = ...; camera.RenderToCubemap(cubemapRT, 63);Camera.RenderToCubemap 의 두번째로 들어가는 인자는 어떤 면을 그릴건지에 대한 비트마스크다. Camera.RenderToCubemap 를 쓸때 주의할 점은 일부 하드웨어에서는 동작하지 않는 기능이라고 한다. 다만 특정한 하드웨어를 기술해 놓지않아서 추측하기는 어렵다. 단순히 추측할 수 있는 것은 MRT 를 지원하지 않거나 아니면 다른 ComputeShader 같은 기능을 사용해 일부 하드웨어에서 안된다고 하는 정도 밖에 없다.
위 예제에서는 RenderTexture 를 사용하였는데, 저렇게 코드에서 처리할 수도 있지만 CustomRenderTexture 를 통해 간편하게 처리할 수도 있다. CustomRenderTexture 는 업데이트 주기를 사용자 임의대로 정할 수 있으므로 꽤나 유용하게 쓰일 수 있다.
참조 자료
-
Using Relplacement Shader
Unity 는 Replacement Shader 라는 렌더링 기능을 지원한다. 이는 Unity 가 Rendering 기능에서 지원하는 약간 Hack 한 테크닉이며 이 기능을 잘 사용하면 쉐이더를 바꿔치기 해서 재미있는 것들을 할 수 있다. Replacement Shader 는 렌더링할 MeshRenderer 들이 가지고 있는 Material 의 Shader 를 사용자가 원하는 것으로 바꾸는 기능이다. 이 기능을 통해 그림자 같은 여러 부가적인 처리를 할 수 있다.
사용하는 방법은 아래와 같다.
Shader shader = Shader.Find("CustomShaderName"); string replacementTag = "replace"; // tag is optional. if dont need tag, insert null. camera.RenderWithShader(shader, replacementTag);위의 간단한 예제는 Replacement Shader 를 사용해 한번 그려주는 예제다. 단순히 Camera.RenderWithShader 를 사용하기 때문에 직접 값을 컨트롤할 때 사용하기 좋다. Replacement Shader 를 영구적으로 세팅하여 자동으로 그려주면 아래와 같이 하면된다.
Shader shader = Shader.Find("CustomShaderName"); string replacementTag = "replace"; // tag is optional. if dont need tag, insert null. camera.SetReplacementShader(shader, replacementTag);사용 방법은 굉장히 단순하다. 다만 이 Replacement Shader 기능에서 중요한 것은 쉐이더를 단순히 치환하는 것만 포인트가 아니다. 치환된 쉐이더들은 기존 Material 이 가지고 있던 데이터들과 쉐이더 코드에서 이름만 똑같이 맞추어주면 자동으로 데이터들이 쉐이더로 들어온다. 즉 쉐이더를 갈아치우지 않고도 데이터를 공유할 수 있는 것이다. 이는 Unity 의 렌더링에서 굉장히 강력한 시스템으로 초기에는 이해하기도 힘들고 잔머리가 필요하지만 이를 잘 사용만 한다면 굉장히 유용하게 쓰일 수 있다.
필자는 Github 에서 OIT 예제를 보면서 처음 보았다. Github : OIT_Lab 에서 OIT 를 처리하는 코드에서 구경할 수 있다. 또한 일본 Unity 지사에서 일하는 유명한 keijiro 의 Skinner 에서 위치를 처리하는데 쓰이기도 한다.
참조 자료
-
Using Compute Buffer In Unity
Unity 에서의 확실한 GPU Instancing 은 ComputeBuffer 라는 구현체에서 시작될 것이다. 이 구현체는 UnityEngine.ComputeBuffer 라는 Unity 의 구현체이며 하는 역할은 GPU 메모리를 사용하게 해주는 역할을 한다. ComputeBuffer 는 ComputeShader 와 함께 등장했다. ComputeShader 에서 데이터를 읽고 쓰는것을 요구하기 때문에 Unity 는 GPU 메모리를 사용하는 컨테이너로서 ComputeBuffer 를 구현해 놓았다. 하지만 이 ComputeBuffer 는 ComputeShader 뿐만아니라 일반 쉐이더에서도 폭넓게 사용가능하다. 이 말의 뜻은 우리가 생각하는 Unity 에서 지원하는 일반적인 메쉬 데이터를 사용하지 않아도 사용자가 직접 메쉬 데이터를 커스터마이징해서 사용할 수 있다는 이야기이다. 지원하는 플랫폼은 일반적으로 말하는 Shader Model 5.0 이상이다. PC 플랫폼에서는 당연히 사용 가능하다.
사용하는 방법 자체는 어렵지 않다. 스크립트에서 size 와 stride 를 설정해주고, 데이터의 배열을 만들어 GPU 메모리 안에 있는 데이터를 읽거나 쓸 수 있다. 메모리 단위에서 하는것처럼 보이기 때문에 크기와 타입은 맞춰주어야 한다. C# 에서는 System.Array 형으로 넣어주니 형태에 주의하기 바란다. 방법은 아래와 같다.
int dataLen = ...; // length of data int[] dataArray = new int[dataLen]; // record data in dataArray.. ComputeShader computeShader = ...; ComptueBuffer dataBuffer = new ComputeBuffer(dataLen, sizeof(int)); dataBuffer.SetData(dataArray); computeShader.SetBuffer("dataBuffer", dataBuffer);위 코드는 ComputeShader 에서 ComputeBuffer 를 사용하기 위해 세팅하는 코드다. 가장 맨처음에는 초기에 세팅할 정수 배열을 만들고, 그 다음 ComputeBuffer 인스턴스를 생성한다. 생성자에서 넣어주는 인자는 데이터의 길이(length)와 각 데이터별 크기(stride)이다. 그 다음 같은 크기의 배열의 데이터를 GPU 메모리로 쓴다.(write) 그리고 마지막으로 데이터가 세팅된 ComputeBuffer 를 ComputeShader 에 연결해준다. 이러면 ComputeShader 코드에서 dataBuffer 라는 변수명을 가진 변수에 ComputeBuffer 가 연결된다. 아래에 ComputeShader 코드가 있다.
StructuredBuffer<int> dataBuffer; [numthreads(8,8,1)] void Process (uint3 id : SV_DispatchThreadID) { ... }맨 처음에 있는 dataBuffer 에 연결된다. StructuredBuffer vs ConstantBuffer 에서본 StructuredBuffer 타입이 가능하다. 또한 RWStructuredBuffer, ConsumeStructuredBuffer, AppendStructuredBuffer 가능하다. 다른 렌더러 쉐이더 코드에서도 사용가능하다. 그래서 일반적으로 고려되는 파이프라인은 아래와 같다.

앞의 두가지 ComputeBuffer 를 세팅하고 ComputeShader 를 실행하는 코드는 대충 보았다, 뒷 부분의 ComputeBuffer 를 통해 렌더링을 하는 것은 그다지 어렵지 않다. 중요한 것은 참신하게, 효율적으로 렌더링하는 것이다.
Github : CustomSkinningExample 에서 스키닝의 계산을 ComputeShader 로 넘겨서 계산한다. 또한 메시 데이터 전체를 ComputeBuffer 로 넘겨서 렌더링하기 때문에 꽤나 괜찮은 예가 될것이다.
참조
-
Darboux Frame
여러 공간 법선 벡터(tangent space normal, object space normal)에 대하여 알아보던 도중 모르는 것이 하나있어 정리해볼겸 포스팅해보려 한다. darboux frame 이라는 놈이다.
-
Normal Tangent Binormal
Graphics 를 공부하다보면 노말(normal), 탄젠트(tangent), 바이노말(binormal) 를 굉장히 많이보게 된다. 특히 노말이라는 단어는 꽤나 많이 보인다. 보통은 어떤 역할을 하는 벡터앞에 이름을 붙여서 말한다. 아래와 같이 정리된다.
-
Optimized Center Of Rotation
이전 dual quaternion skinning 글에서 dual quaternion skinning 에 대해서 설명해 보았다. 이전 글에서는 단순히 dual quaternion skinning 에 대해서 알아보고 장점에 대해서 알아보았다. 단점에 대해서는 언급을 하지않았는데 사실 단점도 존재하긴 한다. 새로 소개할 방법의 논문에서 dual quaternion skinning 의 단점에 대해서 언급했다.
joint bulging artifact 라고 하는 것인데, 90도 정도 휜 부분의 바깥쪽이 튀어나오는 현상을 말한다. 아래 그림에서 볼 수 있다.
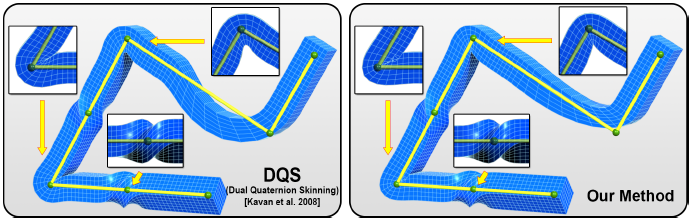
왼쪽은 dual quaternion skinning 을 표현한 그림이고, 오른쪽은 곧 소개할 optimized center of rotation 방법이 적용된 스키닝이다. 각 그림의 오른쪽의 90도 휜 부분을 관찰하면 dual quternion skinning 이 약간 아래가 부푼 모습을 볼 수 있다. 이를 joint bulging artifact 라고 한다. 그리고 오른쪽 위의 확대된 그림을 보면 dual quaternion skinning 은 약간 움푹 들어간 것을 볼 수 있다.
그래서 디즈니 리서치라는 연구소에서 새로운 방법을 2016 년 Siggraph 에서 소개했다. 논문의 이름은 Real-time Skeletal Skinning with Optimized Centers of Rotation 이다.
-
Dual Quaternion Skinning
이전 Introduce of skinning 글에서 Skinning 에 대한 설명과 LBS 에 관한 내용을 간단하게 다루어 보았다. 하지만 글 마지막에 해결되지 않은 문제가 하나 있었다. Linear Blend Skinning 의 “Candy Wrapper” 라는 현상이였는데, 이 글에서는 그 문제를 위해 2008년에 고안된 방법에 대해서 알아볼 것이다.
-
Introduce Of Skinning
2달전 쯤에 스키닝에 대한 글을 본적이 있다. 그때는 스키닝이 뭔지도 정확히 모르던 시점이였다. Unity 에서는 LBS 라는 방법으로 스키닝을 지원하는데 이 방식보다 나은 방식이 있는데 어찌하여 옛날 방식을 지원하는지에 대한 불만글이였다. 그래서 공부할 것을 찾던 필자는 Unity 에서의 커스텀 스키닝을 구현을 목표로 잡았다. 정리를 위해 하나하나 글을 남겨보도록 하겠다. 이 글에서는 간단히 스키닝의 개념에 대해서 써보도록 하겠다. 이전에 쓴 handling rig and skinning 에서도 간략하게 다루었지만 기초 지식이 없는 상태에서 급하게 쓴 글이였고, 굉장히 Unity 스러운 글이기에 다시 처음부터 써보겠다.